On Friday 13th of July, the Royal College of Physicians (RCP), a British professional body dedicated to improving the practice of medicine, is due to release the safe medical staffing report, a comprehensive set of guidelines to improve current working standards and staffing within hospitals. It is now easily observable how secondary healthcare systems, both within the UK and abroad, are under increasing pressure. This is mostly due to growing patient admissions and a decline in available beds, along with an increase in the complexity of conditions and their necessary treatments. Arguably, healthcare systems must undergo major changes and optimise the use of limited (often human) resources, and the RCP seems to be in strong agreement with this interpretation of the current situation. Its large body of physicians and professionals has long been working in order to make positive contributions, helping to ease the working conditions of medical staff and improve the experiences of patients across this country.
On this occasion, the soon to be published staffing report will feature contributions borrowed from the extensive research of an interdisciplinary academic group of engineers, doctors, human factor researches and mathematicians within the University of Nottingham (see https://wayward.wp.horizon.ac.uk/). I have myself had the privilege of being part of this great team during the last 2 years. As a mathematician, I must confess this has been challenging at times; especially, when navigating through rooms full of clinicians, nurses and various stakeholders, trying to make sense of the important real-world challenges they face during their everyday life. In addition to that, I have experienced at several times how these professionals, with their different backgrounds, interests and opinions, often find it hard to grasp the exact nature of the work that a bunch of statisticians and scientists of the sort can do, and how it is we can contribute to very topical matters such as this one. If we don’t make a good job of communicating our work, we risk facing scepticism and marginalization.
Thus, I would like to bring your attention to the fact that, the soon to be released RCP staffing report directly features outputs and key insights offered by statistical tools in the domains of queueing theory, Bayesian inference and Markov chain Monte Carlo, just to name a few. Luckily, there is no real reason why you should go on to Google these keywords; at times, it is up to us to abstract you from the technicalities and complex concepts, and put the focus on informative key findings that bring something to the table. Hence, I thought I would provide a few of the insights that came out of our data analyses and discussions with the various great teams at the Nottingham University Hospitals NHS Trust. The results here are only representative of the hospitals analysed, and data used was gathered during a 4 year time-span, from two major university hospitals jointly providing secondary healthcare to over 2.5 million residents in the United Kingdom. At the end of the post, you will find a list of references to some engineering, statistics and computer science publications that offer a rather comprehensive look at the (exciting!) mathematics lying at the heart of this work.

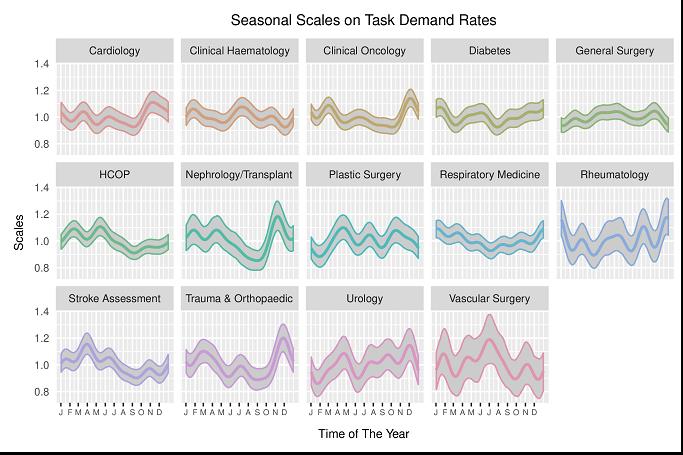
Have a look at the two figures above – you will find a bunch of colourful graphs showing what are seemingly temporal patterns distributed across various medical disciplines. The technical name to these is “Bayesian posterior credible intervals” – on a basic level, this is simply Bayesian analogue to a confidence interval, a.k.a. our favourite concept in that dreaded Year-1 statistics class. These ones reflect variations on average patterns of task demand in the hospitals, both weekly and year-round. Most importantly, these are not descriptive results, i.e. they don’t just average data here and there, nor are they built on strong assumptions common in practical low-level models. These results are extracted from a model of high complexity accounting for day-to-day dependence, random noise, distribution of observations … and the outputs reflect uncertainty regarding our confidence in the scales. So, why is this important? Why did the RCP or other physicians care? After all, they are nothing but confidence intervals, they tell us nothing for sure!
And that is precisely the point here. Patient arrivals, task demands, discharges, treatment times … these are all subject to such great noise. Ultimately, day-to-day work-demand within hospitals is, to a good extent, fairly unpredictable. As a consequence, every individual builds an (often very biased) opinion on the requirements, demands and plan of action necessary, usually based on their personal experiences. Hence, they have no means to factor for objective measures of certainty regarding what is predictable, and to what extent. In addition, they are good doctors, who devote their time to gain the skills that can ensure puts us on good hands; it is only to be expected that they have no expertise on designing the advanced mathematical frameworks that can offer an overview on workload, that is free of (most) sources of bias.
[1] Perez, I., Hodge, D., & Kypraios, T. (2017). Auxiliary variables for Bayesian inference in multi-class queueing networks. Statistics and Computing, 1-14
[2] Perez, I., Pinchin, J., Brown, M., Blum, J., & Sharples, S. (2016). Unsupervised labelling of sequential data for location identification in indoor environments. Expert Systems with Applications, 61, 386-393.
[3] Perez, I., Brown, M., Pinchin, J., Martindale, S., Sharples, S., Shaw, D., & Blakey, J. (2016). Out of hours workload management: Bayesian inference for decision support in secondary care. Artificial intelligence in medicine, 73, 34-44.


 Georgiana Nica-Avram
Georgiana Nica-Avram Horia Maior
Horia Maior Helena Webb
Helena Webb Neelima Sailaja
Neelima Sailaja