
Land-use classification is an essential environmental activity that involves mapping an area according to the characteristics of the land. This is very useful because it provides information on the types of human activity being carried out in an area. The information in these maps can be then used to study the environmental impact that different planning decisions may have on a community. For example, national agencies will use land-use maps showing industrial, rural and residential areas to decide where different facilities, such as hospitals, or energy plants, or access, such as roads, should be built.
Different classifications can be used, depending on the level of detail needed. Simple classifications may distinguish two classes: buildings and non-buildings. More detailed classifications can include up to nine classes: urban, industrial, formal residential, informal residential, slums, roads, vegetation, barren, and water bodies.
While simpler classifications are easier to obtain, more detailed classifications offer a wider range of information and give a richer picture of the underlying organisation of an area. Nevertheless, while extremely useful, obtaining detailed land-use maps is no easy feat. The most accurate option remains employing human surveyors, who must be trained and are then required to travel to the area to be mapped, pen and paper in hand. As a consequence, manual classification can be subjective, time-consuming, labour-intensive and expensive.
The caveats are specially challenging in fast-developing cities with under-resourced local government. In these areas, centrally-organised mapping is difficult to maintain up to date due to lack of personnel and fast-paced changes in land purpose. Consequently, these areas could benefit from having an automatic way to produce land-use classification maps that is cost-effective, accurate, fast and easy to produce and maintain.
That was the purpose of the DeepNeoDem project. This AGILE project was a collaboration between Horizon Digital Economy Research, the NeoDemographics Lab at the Business School, and the Computer Vision Lab at the School of Computer Science. We used Fully Convolutional Networks (Long et al.; 2015) and drone imagery collected as part of the Dar Ramani Huria project, to show that it is possible to obtain accurate detailed classifications of up to nine different land-use classes.
Interesting results showed that, in some cases, such as the one showed in the figure below, FCNs were able to even beat human annotators, by picking up vegetation and roads which had not been annotated by humans.
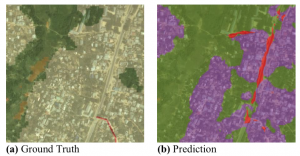
Figure 1. FCNs are able to learn roads (red) that are not present in the manual annotations, as well as finding patches of vegetation (green) than were not annotated.
You can find more information in: “Automatic Pixel-Level Land-use Prediction Using Deep Convolutional Neural Networks” by M. Torres Torres, B. Perrat, M. Iliffe, J. Goulding and M. Valstar. Link here.
References:
[1] Long, J., Shelhamer, E. and Darrell, T., (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3431-3440).
Mercedes Torres Torres, Transitional Assistant Professor, Horizon Digital Economy Research